Roto-translation covariant convolutional networks for medical image analysis
Building upon research that started in 2014 with a project on object recognition via template matching in orientation scores [1,2], which eventual resulted in our IEEE tPAMI paper [3], we have now published work on group convolutional neural networks [4]. In [4] we propose group-convolution layers that are equivariant (the ouput transforms accordingly) with respect to rotations and translations of the input. The paper was accepted for oral presentation (top 4% of all submissions) at MICCAI 2018 and contributed to a Philips Impact Award at MIDL 2018 and Young Researcher Award at MICCAI 2018.
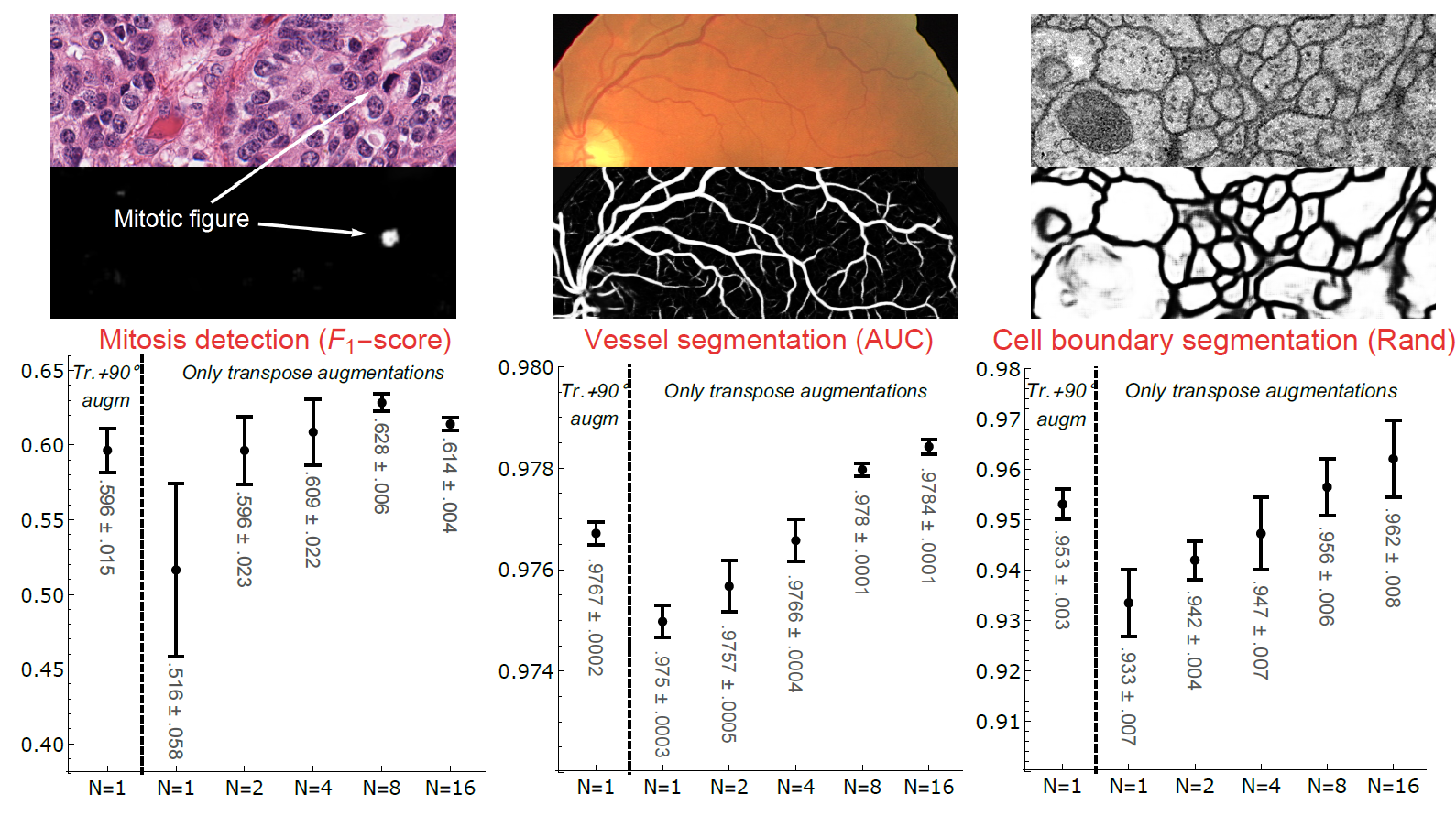
We show with three different problems in histopathology, retinal imaging, and electron microscopy that with the proposed group CNNs, state-of-the-art performance can be achieved, without the need for data augmentation by rotation and with increased performance compared to standard CNNs that do rely on augmentation. The pre-print is available here.
Some notes on the proposed SE(2) CNN layer
For full details see:
Bekkers, E.J., Lafarge, M.W., Veta, M., Eppenhof, A.J., Pluim, P.W., Duits, R.: Roto-Translation Covariant Convolutional Networks for Medical Image Analysis. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. Ed. by Alejandro F. Frangi, Julia A. Schnabel, Christos Davatzikos, Carlos Alberola-Lopez, and Gabor Fichtinger. Cham: Springer International Publishing, 2018, pp. 440–448. Available at: https://arxiv.org/abs/1804.03393
BibTex source:
@inproceedings{bekkers_roto-translation_2018,
title = {Roto-{Translation} {Covariant} {Convolutional} {Networks} for {Medical} {Image} {Analysis}},
copyright = {All rights reserved},
isbn = {978-3-030-00928-1},
url = {https://arxiv.org/pdf/1804.03393.pdf},
booktitle = {Medical {Image} {Computing} and {Computer} {Assisted} {Intervention} – {MICCAI} 2018},
publisher = {Springer International Publishing},
author = {Bekkers, Erik J and Lafarge, Maxime W and Veta, Mitko and Eppenhof, Koen A J and Pluim, Josien P W and Duits, Remco},
editor = {Frangi, Alejandro F. and Schnabel, Julia A. and Davatzikos, Christos and Alberola-López, Carlos and Fichtinger, Gabor},
year = {2018},
pages = {440--448}
}
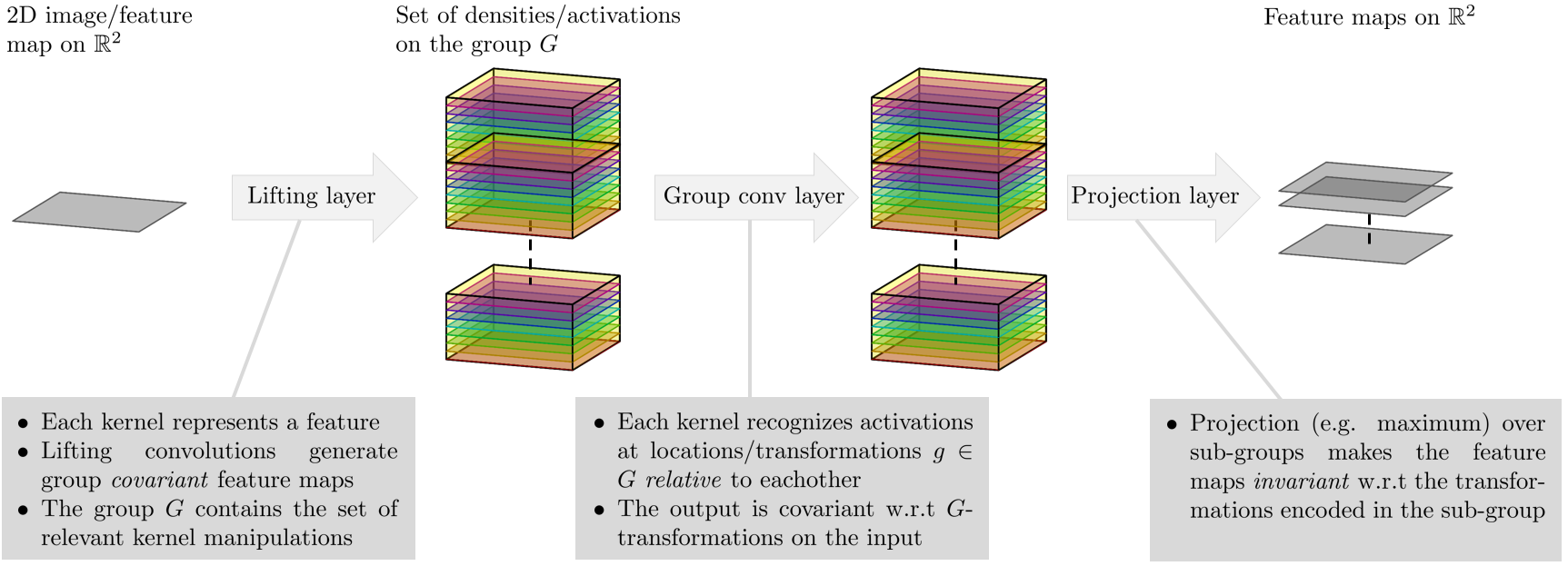
Group convolutional networks
The library (available at our GitHub page) provides code for building group equivariant convolutional networks for the case when the group G is SE(2), the group of planar roto-translations. In this case the lifting layer (se2cnn.layers.z2_se2n) probes the 2D input with rotated and translated versions of the convolution kernels. The data is thus lifted to the space of positions and orientations. In order to make the following layers (se2cnn.layers.se2n_se2n) equivariant with respect to rotations and translations of the input these layers are defined in terms of the left-regular representation of SE(2) on SE(2)-images. The kernels used in the layers are trained to recognize the (joint) activations of positions and orientations relative to each other. Finally, in order to make the entire network invariant to certain transformations one can decide to apply max-pooling (tf.reduce_max) over sub-groups. In our case we might for example do a maximum projection over the sub-group of rotations in order to make the network locally rotation invariant.
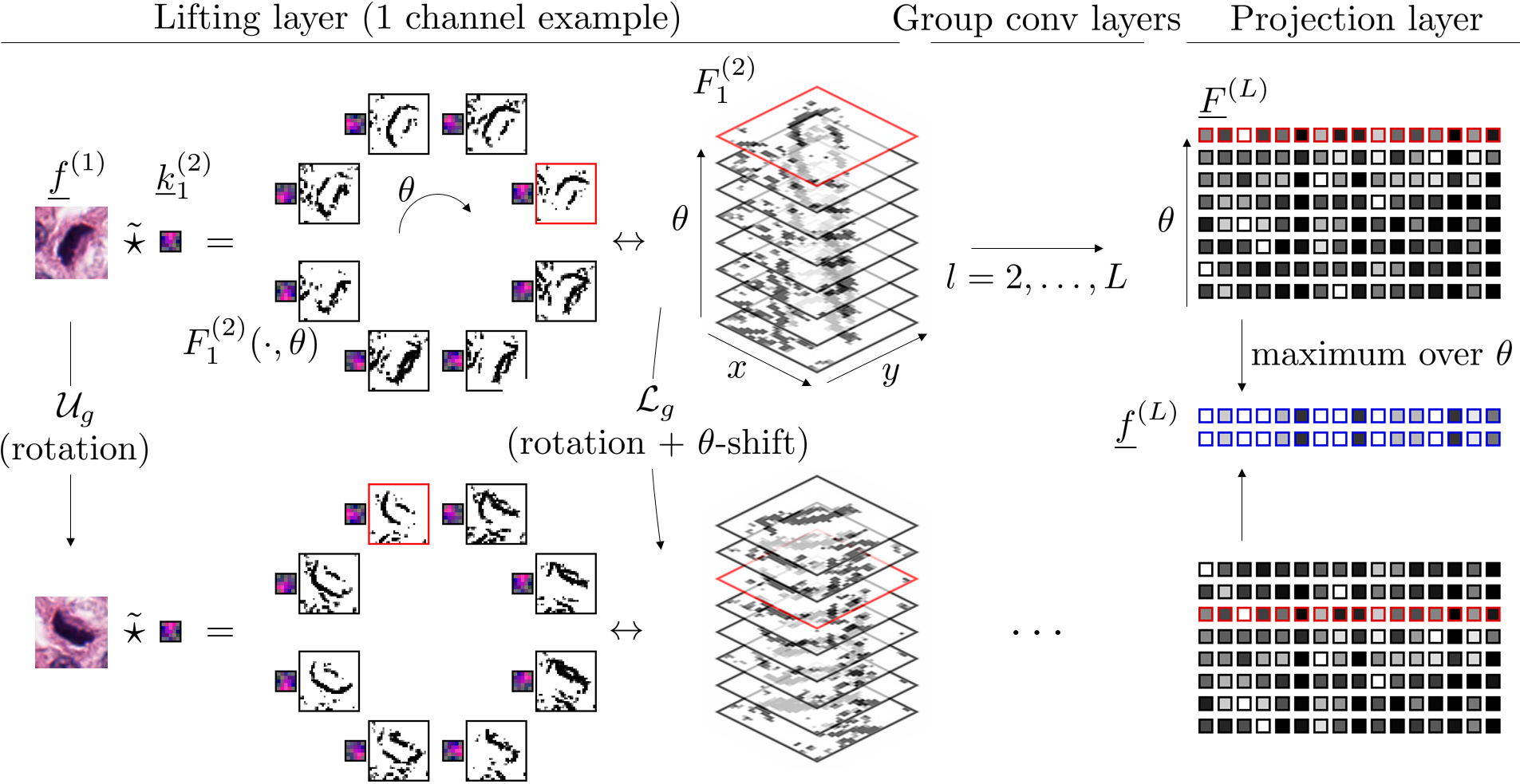
SE(2) convolutional networks
The figure below illustrates some of the layers in a SE(2) CNN. Top row: the activations after the lifting convolutions with a single kernel which stacked together it yields an SE(2) image. The projection layer at the end of the pipeline gives a rotation invariant feature vector. Bottom row: the same figures with a rotated input.
Results
In the figure below the top row shows crop out images of the three tasks considered in our paper with the class probabilities generated by our SE(2) CNNs. The bottom row shows the mean results (+- standard deviation) for several sampling resolutions of the 1-sphere (N=1 corresponds to the standard 2D case). The proposed networks do not require data-augmentation by rotation. Moreover, with an equal amount of trainable weights they outperform the corresponding 2D networks that do rely on data augmentation.